推荐系统多场景联合建模经验
推荐系统多场景联合建模经验
1.前言
设计范式(Design Pattern)是各位码农都应该熟悉的概念。Design Pattern针对软件开发普遍存在的各种问题,提出可复用解决方案。同时,Design Pattern也为程序员之间的交流提供了共同语言。比如,我说我的程序采用了Template Method模式,其他程序员就能对我的程序结构猜个八九不离十。
其实,在我们设计推荐算法模型的时候,也有很多设计范式,比如:
遇到稀疏特征,就想到先embedding,上面再接上mlp;
双塔是“召回”或“粗排”的首选;
看到user action history,就想给它们加上个target-attention或self-attention;
......
在工程化做得好的团队里,以上这些“范式”已经模块化、服务化,高度复用,基本可以做到“开箱即用”。另外,它们也为我们算法同仁提供了共同语言,比如只要提到“双塔”这两个字,它的网络结构、应用场景、优缺点就都出现在我的脑海中,不用再费口舌了。
本文总结归纳一种新的推荐模型的设计范式,区区不才,我将之命名为“动态权重”(Dynamic Weight,DW)。这种范式被多个团队实践并公开发表过,只不过是在不同的论文里,起着不同的名字,针对不同的问题而提出。因此,这些之前孤立的成果,缺乏串联、归纳和总结,不为广大算法同行所熟悉。本文试图补上这一环节,为这种新的设计范式“摇旗呐喊”,希望能启发更多的算法同行。
2.动态权重模式
2.1 问题
我在《先入为主:将先验知识注入推荐模型》 就明确指出,大型推荐系统要面对多场景,而多场景的训练数据存在分布差异。比如:
对一个跨国app,不同国家的用户的消费习惯存在差异;
同一个app,不同使用场景,比如单列 vs. 双列,用户行为也有较大差异;
新老用户的行为模式也存在很大的不同。
面对这种差异,一种作法是将拆分数据,每个场景(不同国家、单双列、新老用户)单独训练、部署模型。但是这种作法也有缺点:
有的场景数据少,单独训练根本训不出来,必须依靠大数据场景的知识迁移;
每个场景,单独训练和推理,资源占用太多,而且日后的升级、维护都比较麻烦。
单独建模行不通,把所有数据合在一起训练就行了吗?最大的问题在于,各个场景的数据量严重不均衡。合一起训练,整个模型会被数据丰富的场景主导,从而在数据量少的场景表现欠佳。
2.2 现状
以上描述的就是,一个多场景推荐系统所面临的“分也不是,合也不是”的两难问题。现阶段,业界应对多场景推荐问题,主要是从“特征”和“结构”两个技术方向上想办法:
特征:
设计多场景之间有明显区分性的特征,或者叫“场景敏感”的特征。比如,多国家场景下,用户和作者的国籍、语言;新老用户场景下,是否新用户、用户是否登录、用户使用天数等。这方面的工作非常重要,但是能做的也不是非常多。
另外,有了这些特征,将它们加入模型的方法也非常讲究。如果和其他特征一同接入DNN的最底层,让信息慢慢向上传,传到最后,这些“场景敏感”特征对最终预测结果还有多少影响力,也不好说了。
结构:
主要是一些多塔结构,每个场景对应一个塔,多塔之间既共享信息,又要避免数据少的塔不被数据多的塔带偏太多。这方面的成果主要有阿里的STAR和HMOE,在我之前的文章《初来乍到:帮助新用户冷启的算法技巧》 已经介绍过了,感兴趣的同学出门左转。
2.3 方法
Dynamic Weight模式是在以上“特征”和“结构”之外开辟了一条新的技术路线,即在DNN Weight上做文章。
将“场景敏感”特征,喂入一个小网络,输出一个向量W,即
W=G(z)。把 reshape成一个子模型Dynamic Weighted Network(DWN)。比如,W一共256维,可以reshape成一个的三层MLP。
拿以上根据“场景敏感”特征动态生成权重的DWN,接入整个推荐模型的关键位置。即,注意这个动态网络的输入是,就是普通特征,场景敏感与非敏感特征都包括。
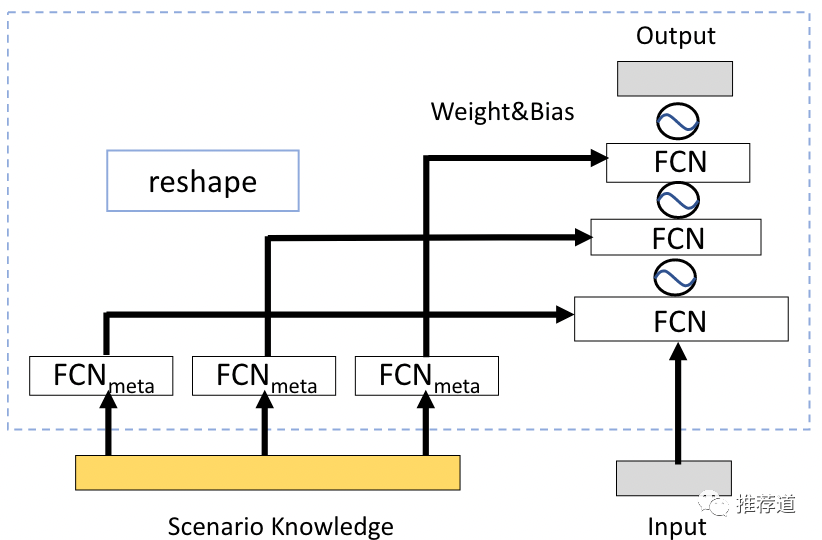
2.4 优点
第一,各个场景的数据还是合在一起训练的,模型参数也只有一套,方便线上维护。而且共享的模型参数,也允许数据丰富场景学习到的知识,向数据稀少的场景迁移。
第二,前文已经讲到过了,“场景敏感”特征如果和其他特征一样喂入DNN的最底层,很容易就“泯然众人矣”。这些“场景敏感”特征的信息,在层层向上传递过程中,被其他特征所干扰,无法对最终预测结果产生多少影响。而DW模式特别突出了“场景敏感”特征的作用,让它们像一个“滤波器”控制住了其他信息的向上传递通道。其他信息向上传递过程中,都要经过“场景敏感”特征的“调制”,根据不同场景,对前一层发现的模式局部放大或衰减。而且在将动态产生的权重reshape成DWN的过程中,DWN层与层之间可以插入非线性的激活函数,从而允许实现比较复杂的“调制”功能。
3. 动态权重的应用
3.1 LHUC
先来谈谈我自己在DW范式上的实践。在我之前的《先入为主:将先验知识注入推荐模型》一文中就提到过“重要特征当裁判”。
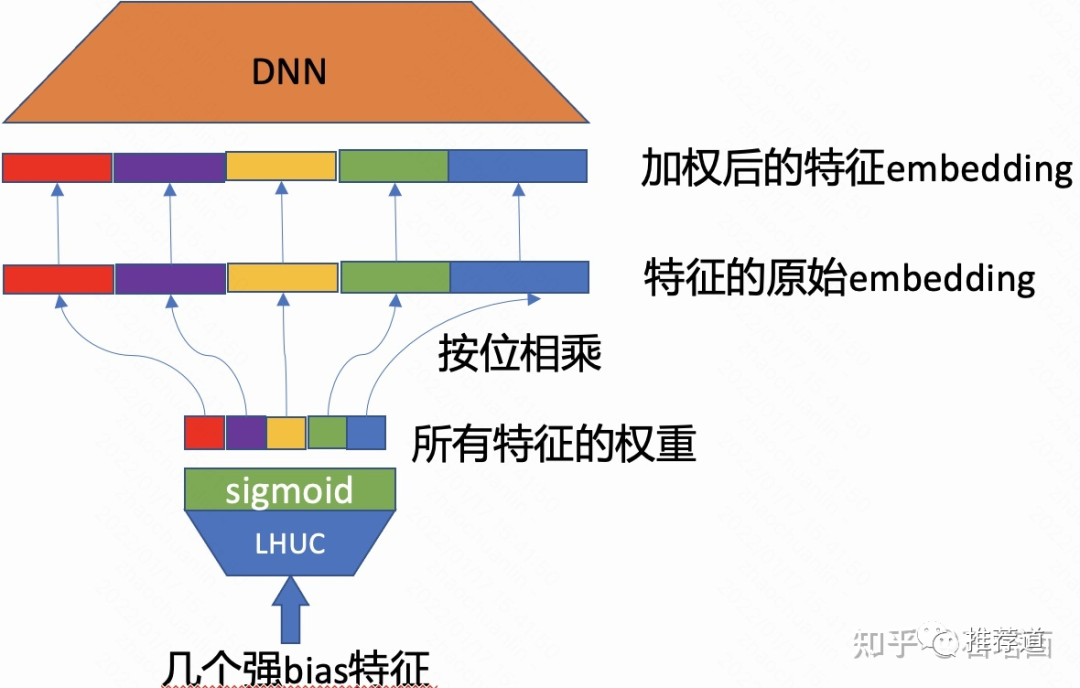
强bias特征作为SENet或LHUC (Learn Hidden Unit Contribution)的输入,经过sigmiod激活函数后,输出是一个维度向量,是所有field的个数;
输出的N维向量代表各field的重要性,将其按位乘到各field的embedding上,起到增强或削弱的作用;
加权后的各field embedding再拼接起来,喂入上层DNN。
当时只觉得是一个trick,现在看来,根据强bias特征生成的各Field的重要性,就是在实现Dynamic Weight范式,只不过DWN只有一层罢了。
3.2 微信的PTUPCDR
微信在2021年发表论文《Personalized Transfer of User Preferences for Cross-domain Recommendation》。其核心思想是,
在做跨域迁移学习时,需要将soruce domain user embedding映射到target domain,即。
传统方法,所有用户都共享一个B(i.e., Bridge),即这个映射函数缺乏个性化。
微信认为,每个用户应该拥有自己的映射函数,即个性化映射函数。
具体作法上,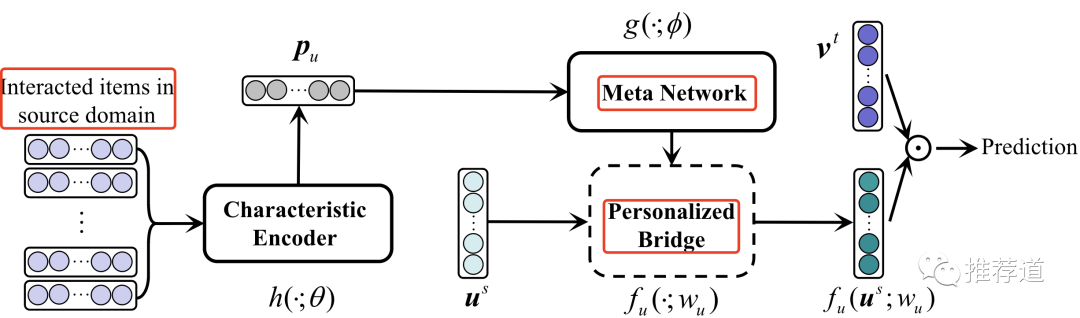
他们将用户在source domain的action sequence喂入一个meta network;
输出的向量reshape成一个Personal Bridge;
再用动态生成的Personal Bridge完成source domain user embedding向target domain的映射,实现“个性化映射”。
3.3 阿里M2M
阿里在2022年2月发表《Leaving No One Behind: A Multi-Scenario Multi-Task Meta Learning Approach for Advertiser Modeling》。M2M针对大型推荐系统的现实痛点,“多目标+多场景”推荐:大型推荐系统要面对多个应用场景,而在每个应用场景下都要预测用户的多种行为(e.g., 点击、观看、收藏、购买、......)。
在应对多目标方面,M2M的作法比较传统,就是普通的MMoE。而在之后的步骤上,M2M采用了Dynamic Weight模式。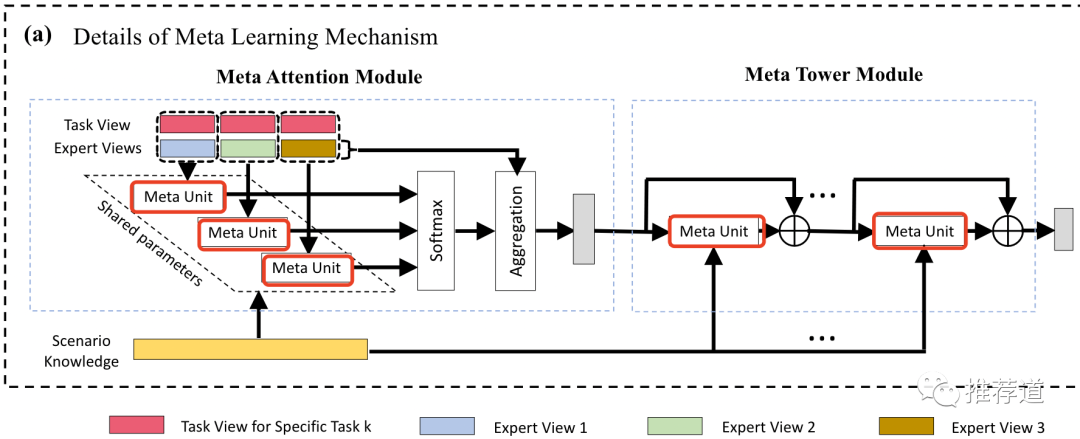
首先,M2M实现了通用模块Meta Unit。这个模块根据“场景”特征,动态生成权重,再reshape成一个MLP。
在整合多个expert的输出时,用Meta Unit代替普通MLP实现Attention决定各expert的权重,让“场景”特征主导多目标的信息整合;
在整合后的expert信息向上传递时,用Meta Unit代替普通MLP实现Residual Network,让“场景”特征控制信息传递。
3.4 阿里APG
阿里在2022年3月发表《APG: Adaptive Parameter Generation Network for Click-Through Rate Prediction》,聚焦Dynamic Weight模式中的性能问题。
假设,一个d维的“场景敏感”特征,喂入一个meta unit,结果reshape成一个的矩阵。 这个环节的主要问题就是,复杂度太高。
这个环节的主要问题就是,复杂度太高。
单单dynamic weight generation这一环节,其时间复杂度和空间复杂度就都是
动态生成weight之后,还要通过矩阵前代,总的时间复杂度变成了
这还只是1层而已,想想M2M中要在多处都用Meta Unit代替MLP
而且实际推荐模型中,很多层的N和M都在“千”这个量级
为了能够将dynamic weight generation这一过程的时间复杂度和空间复杂度降下来,APG提出了由4个步骤组成的Re-parameterization。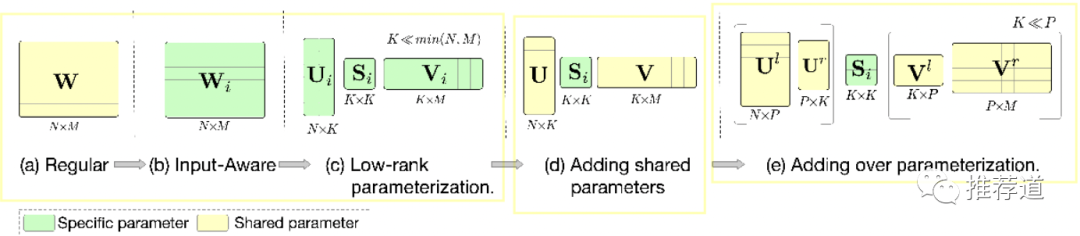
3.4.1 步骤1: low-rank parameterization
根据“场景敏感”特征动态生成的不再是一个大矩阵,而是三个小矩阵矩阵。理论上这三个小矩阵相乘的结果就等于原来的大矩阵,但是
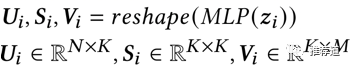
3.4.2 步骤2: decomposed feedforwarding
有了U、S、V这三个小矩阵,在前代的时候,不用重新将USV相乘重组成W再前代,而是将U、S、V依次使用于输入。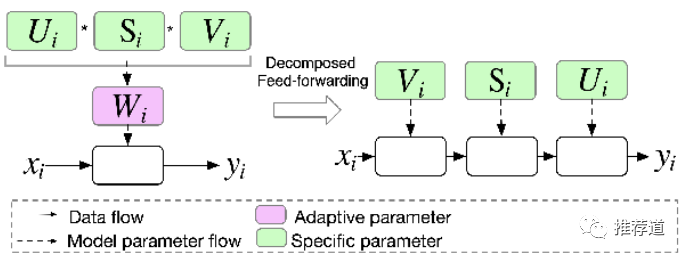
3.4.3 步骤3: Parameter sharing
为了进一步减少复杂度,分解的三个小矩阵中,
只有中间的小方阵S是由动态生成
U和V不再针对不同场景动态生成,而是static defined,并为多场景共享
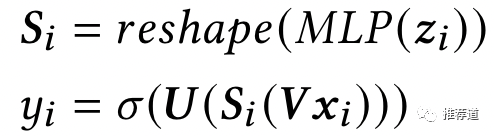
3.4.4 步骤4: Over Parameterization
因为U & V变成了static defined,而U和V有一维是K,而K << min(N,M)。APG又嫌弃U和V的表达能力不足,人为增加更多的学习参数。(这个操作有点迷:-c)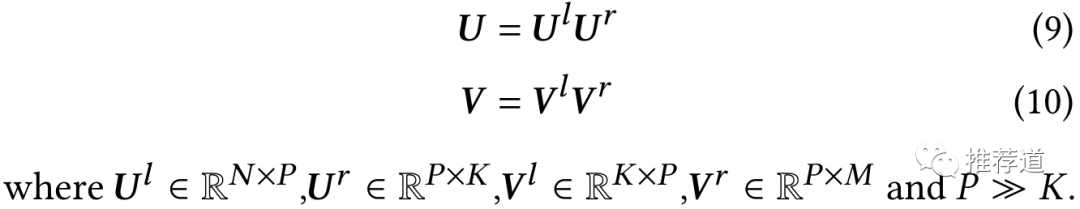
总之,我觉得APG提出的Dynamic Weight的性能问题,的确很重要,值得重视。但是,是否采用APG这种作法,还是“见仁见智”吧。大不了,没必要到处使用DW,只在关键环节使用就可以了。
4.总结
本文归纳总结了名为Dynamic Weight (DW)的推荐模型设计范式:
DW针对多场景推荐问题。
DW根据“场景敏感”特征动态生成一个MLP的权重,代替普通MLP接入推荐模型的关键位置。
DW突出“场景敏感”的作用。其他信息向上传递过程中,都要经过“场景敏感”特征的“调制”,根据不同场景,对前一层发现的模式局部放大或衰减。
DW已经被腾讯、阿里多个团队投入实践,取得一定效果。
看到这里,了解阿里Co-Action Network(CAN)的同学,是不是有一种似曾相识的感觉:
CAN和DW针对的问题很像,都是针对“合不上,分不开”的问题
这和DW为每个场景单独建模,面临的“数据少场景不好训、占用资源多、不好维护”问题,很相似。
这和DW将所有场景数据合一起训练,面临的“模型被数据多的场景带偏”问题,很相似。
合不上:如果每个特征只有一套embedding,需要与其他所有embedding交叉,可能相互干扰。
分不开:如果每对儿交叉特征都有自己独立的embedding,特征空间太稀疏不好训,而且也占用太多资源。
CAN和DW解决的方法很像:
CAN把target item id/category embedding reshape成一个MLP,与user feature交叉时,就把user feature喂入这个dynamic generated MLP;
DW利用“特征敏感”特征动态生成一个MLP,把其他所有特征喂入这个dynamic generated MLP。
CAN和DW,如此相似,可谓“英雄所见略同”。
一门学科中出现“设计范式”,也就是套路,是这门学科成熟的标志。当然,目前的推荐算法,不仅成熟,而且还有点熟透了,都卷了。看到这里,也面临多场景推荐问题的同学,可以在自己的项目中卷一下Dynamic Weight了。至于效果如何,还是那句老话,等待GPU和AB平台告诉我们答案吧。